在大数据时代,Hadoop主要用来处理非结构化数据,而如何处理传统IOE架构的结构化数据则成为企业面临的一个难题。在此背景下,既能处理结构化数据又能处理非结构化数据的SQL on Hadoop应运而生。
SQL on Hadoop是2013年最热门的话题,它由Cloudera Impala的发布版推到热议。目前,SQL on Hadoop正处于起步阶段,其技术实践方式很多样。而企业由于已经适应了在小数据上的灵活处理方式,转到Hadoop一下子变得无所适从,所以对SQL on Hadoop的呼声越来越大。SQL on Hadoop既要保证Hadoop性能,又要保证SQL的灵活性。关于SQL on Hadoop,业界有不同的看法,业内专业大数据公司也在积极的研究。
1.传统方式的DB on TOP
一些北美厂商采用传统方式的DB on TOP来解决SQL on Hadoop,即组合利用不同的计算框架面向不同的数据操作。其中以EMC Greenplum、Hadapt、Citus Data为代表。Hadapt以PostgreSQL架接在Hadoop上,来完成对结构化数据的查询。它提供了统一的数据处理环境,利用Hadoop的高扩展性和关系数据库的高速性,分开执行Hadoop和关系数据库之间的查询。Citus Data通过把多种数据类型转化成数据库的原生类型,运用分布式处理技术来完成查询。
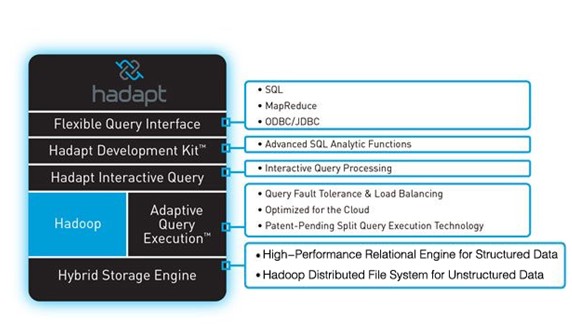
图1、Hadapt
DB on Top 方式是业内同事解决结构化与非结构化数据的最初尝试,最早由Hadapt公司在2010年提出,也就绪了能够跑在Amazon EMR上的社区版。但是,其本质是数据在两种计算框架中分别存放,如图1所示,结构化数据存储于高性能关系型数据引擎(High-Performance Relational Engine for Structured Data),非结构化数据存储于Hadoop分布文件系统(Hadoop Distributed File System for Unstructured Data),对两种类型的数据交互依靠查询的切片执行,元数据的组织控制必然是系统扩展演变中的过度技术。
来源:vacloud.cn





